ETL Part I: Apache Beam, Eclipse, Google Cloud Storage and BigQuery
In this article we will Extract data (youtubedata.csv file) from Google Cloud Storage, Transform it with Apache Beam and load the results into BigQuery using Eclipse —as we journey into revealing the top 5 categories with maximum number of videos uploaded, the top 10 rated Videos, and the most viewed Video.
For the sake of simplicity we will stick to a single extraction source.
Prerequisites
- Some Java knowledge
- Eclipse IDE and Cloud Tools for Eclipse Plugin: Follow [1] to set up
- GCP Project: to get a free tier GCP account with $300 free credits visit [2] → click on the button which says “get started for free” and follow the instructions or [3] → Create a project and name it beam-training905
- Set up Cloud Dataflow in Eclipse following [4]
- Download the youtubedata.csv file here [5]
Cloud Storage Bucket Set Up

Google Cloud Storage is a service for storing your objects in Google Cloud. An object is an immutable piece of data consisting of a file of any format. You store objects [e.g youtubedata.csv] in containers called buckets. All buckets are associated with a project [beam-training905 in our case].
Create a new standard bucket in your project [beam-training905] following the steps in [6] → Console or running the command “gsutil mb gs://BUCKET_NAME” in your cloudshell. BUCKET_NAME is the name you want to give your bucket. My BUCKET_NAMEis beam_trainings369.
Note: Every bucket name must be unique. With that in mind we will refer to beam_trainings369 as your created BUCKET_NAME…. See [7] for more bucket name requirements.
The result looks like….

Select → beam_trainings369 → CREATE FOLDER→ name = input → CREATE → input/ → UPLOAD FILES → Locate the youtubedata.csv file in your system and upload
The result looks like…..

Select → youtubedata.csv → Copy the URI value as we will need it during Extract


Select → Navigation Menu → I AM & ADMIN → Service Accounts → Actions → The three dots ⋮ on the Compute Engine default service account → Create Key → Key type = JSON → CREATE.
Note: Where the downloaded key file [we will refer to it as beam-training905.json] is located in your system

Inside Eclipse: Select → File → New → Project → Google Cloud Data Flow Project → Fill in the blanks like the bellow image with the project template = “Starter project with a simple pipeline” → Next


Set → Cloud Storage Staging Location = the createdBUCKET_NAME
Set → Service account key = beam-training905.json → Finish
Inside the package explorer → Select → daily package → src/main/java → com.training_harder.daily → Create a new Java class named SamplePipeLine.java
WHAT IS APACHE BEAM?

We have just created a Google Cloud Dataflow Project — meaning we will be using the Dataflow Runner to execute our code.
Dataflow is a serverless execution service from Google Cloud Platform for data-processing pipelines written in Apache Beam. Apache Beam is an open-source, unified model for defining both batch and streaming data-parallel processing pipelines.
Note: The Beam programming model is designed around several key concepts including Pipeline, PCollection, PTransforms, ParDo, Pipeline I/O, Aggregation, User-defined functions, Runner, and Triggers. Visit product documentation to learn more…
Import into SamplePipeLine.java
import java.util.*;
import org.apache.beam.sdk.Pipeline;
import org.apache.beam.sdk.io.TextIO;
import org.apache.beam.sdk.io.gcp.bigquery.BigQueryIO;
import org.apache.beam.sdk.options.PipelineOptionsFactory;
import org.apache.beam.sdk.transforms.*;
import org.apache.beam.sdk.values.PCollection;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import com.google.api.services.bigquery.Bigquery.Datasets.List;
import com.google.api.services.bigquery.model.TableFieldSchema;
import com.google.api.services.bigquery.model.TableRow;
import com.google.api.services.bigquery.model.TableSchema;
import com.training_harder.daily.SamplePipeLine;Paste the following Code with comment description inside Class SamplePipeLine { }
private static final Logger LOG = LoggerFactory.getLogger(SimplePipeline.class);public static void main(String[] args) {//Create a Pipeline
Pipeline p = Pipeline.create();
/** Create an input PCollection of type String to store the contents of youtubedata.csv from applying a read Transform on the early created Cloud Storage bucket = beam_trainings369.
If you are coming from a Spark background think of PCollection as your RDD **/PCollection<String> pInput = p.apply(TextIO.read().from("gs://beam_trainings369/input/youtubedata.csv"));/** You can use a ParDo Transform to consider each element in a PCollection and either manipulate and output that element to a new Pcollection or discard it....Here we apply a pardo Transform with void return -- we just print the file contents **/pInput.apply(ParDo.of(new DoFn<String, Void>() {
@ProcessElement
public void processElement(ProcessContext c) {
System.out.println(c.element());
}
}));p.run();}
Select → Run → Run As → Dataflow Pipeline → notice how messy the printed data looks?
No worries — At least we know the meaning of the first 9 Columns:
Column1 = VideoId --> Type String
Column2 = Uploaded By --> Type String
Column3 = Interval between day of establishment of Youtube and the upload date of the video --> Integer
Column4 = Video Category --> String
Column5 = Video length --> Integer
Column6 = Video Views --> Integer
Column7 = Video Ratings --> Float
Column8 = Number of ratings given --> Integer
Column9 = Number of video comments --> IntegerWe are only interested in rows with Columns 1, 2, 4, 5, 6, 7, 8, and 9 having no null value for our BigQuery Table.
Inside the processElement(ProcessContext c) pardo transform method delete → System.out.println(c.element()); and paste the following code. Read the comments for explanations.
//Split Strings on multiple spaces
String[] arra = c.element().trim().split("\\s+");/** Eliminate rows with non-null value columns less than 8 by checking arrays with length greater than 7 **/if(arra.length > 7) {
/** Here we avoid splitting values separated by "&" like "News & Politics" into arra[3], arra[4], arra[5]
instead of Arra[4] = "News&Politics" **/
String add;if(arra[4].equals("&")) {add = arra[3]+arra[4]+arra[5];
arra[4] = add;System.out.println(arra[0] +", " + arra[1] +", " + arra[4] +", " + arra[6] +", " +arra[7] +", "+ arra[8] +", " +arra[9]);
} else {System.out.println(arra[0] +", " + arra[1] +", " + arra[3] +", " + arra[4] +", " + arra[5] +", " + arra[6] +", " +arra[7]);
}
}
Select → Run → Run As → Dataflow Pipeline
In the package explorer Select → daily package → src/main/java → com.training_harder.daily → Create a new Java Interface named MyOption

Inside the main method create the PipeLine with type MyOption interface named myOptions — having Dataflow PipeLine options. Pass myOptions into Pipeline p = Pipeline.create() as follow…
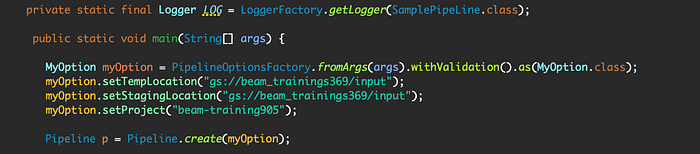
Note: TempLocation = gcpTempLocation → A Cloud Storage path for Dataflow to stage any temporary files. You must create this bucket ahead of time, before running your pipeline. In case you don't specify gcpTempLocation, you can specify the pipeline option tempLocation and then gcpTempLocation will be set to the value of tempLocation. If neither are specified, a default gcpTempLocation will be created. | StagingLocation = A Cloud Storage bucket for Dataflow to stage your binary files. If you do not set this option, what you specified for the tempLocation will be used for the staging location as well. | Project = your Google Cloud project ID

BigQuery is Google’s highly-scalable, serverless and cost-effective solution for enterprise interested in collecting data and storing data. You can view BigQuery as a cloud based data warehouse machine learning and BI Engine features.
Inside your GCP Project Select → Navigation Menu → BigQuery → beam-training905→ CREATE DATASET → Name = learn_bream_daily. You can follow [8].
Some Bigquery concepts to note:
Tables have rows (TableRow) and each row has cells (TableCell). A table has a schema (TableSchema), which in turn describes the schema of each cell (TableFieldSchema). The terms field and cell are used interchangeably.
~ TableSchema: Describes the schema (types and order) for values in each row. Has one attribute, ‘field’, which is list of TableFieldSchema objects.
~ TableFieldSchema: Describes the schema (type, name) for one field.
Has several attributes, including ‘name’ and ‘type’. Common values for
the type attribute are: ‘STRING’, ‘INTEGER’, ‘FLOAT’, ‘BOOLEAN’.
~ TableRow: Holds all values in a table row. Has one attribute, ‘f’, which is a
list of TableCell instances.
Select → learn_bream_daily → CREATE TABLE → Table Name = youtubedata → Add Field → fill in the following image information per field → Create Table

Inside the main method bellow Pipeline p = Pipeline.create(myOption) — create a list of type TableFieldSchema for every column named columns . Each TableFieldSchema object matching as it represents a field in our destination BigQuery table.

Change DoFn<String, Void>() to DoFn<String, TableRow>()Add the missing code into the if(arra.length > 7) as follow

Replace })); with
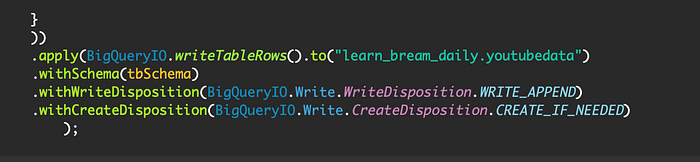
Full Code:
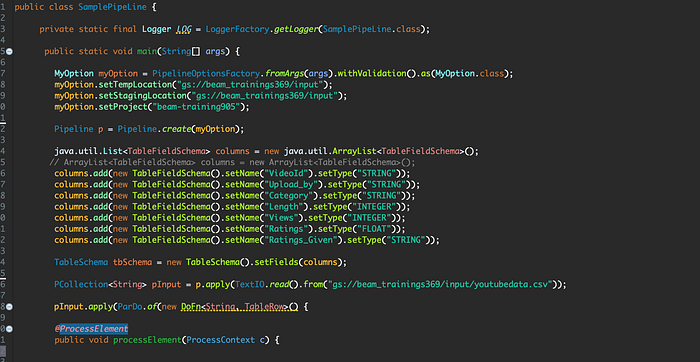
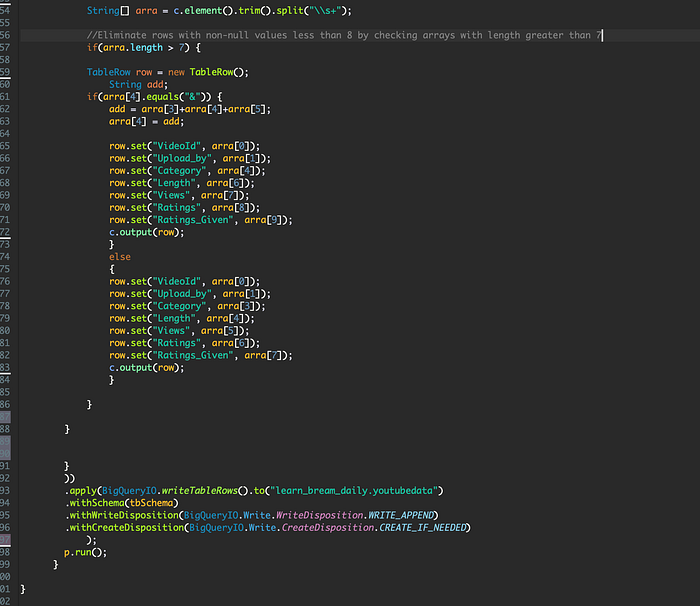
Select → Run → Run As → Dataflow Pipeline
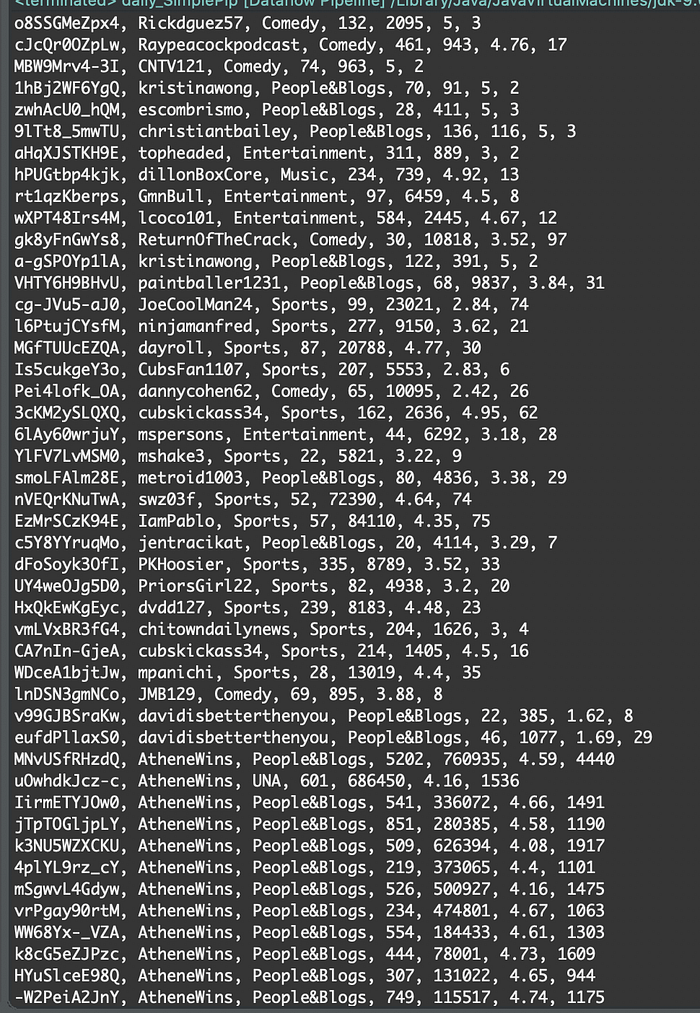
BigQuery Results…..
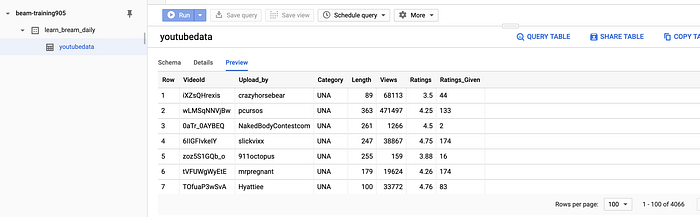
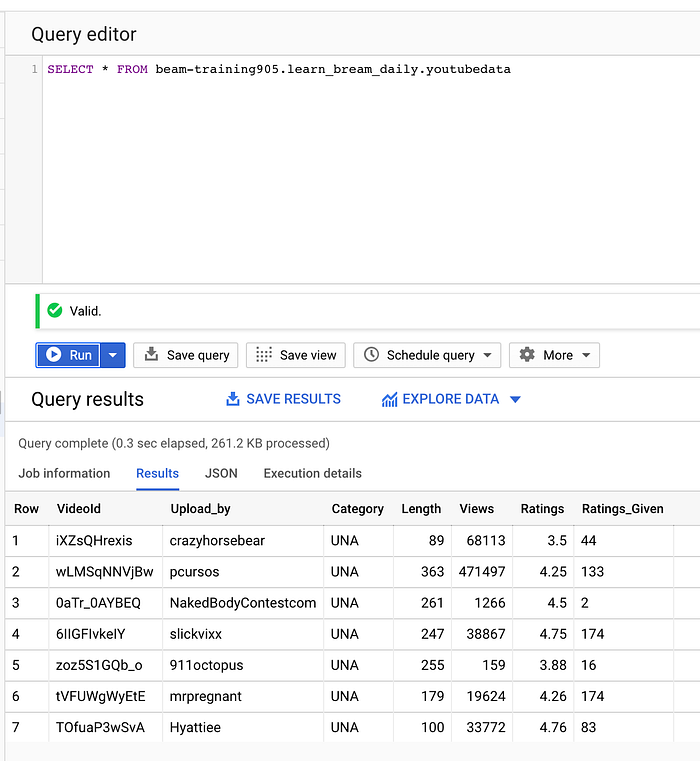
Select from ProjectId.dataset.table
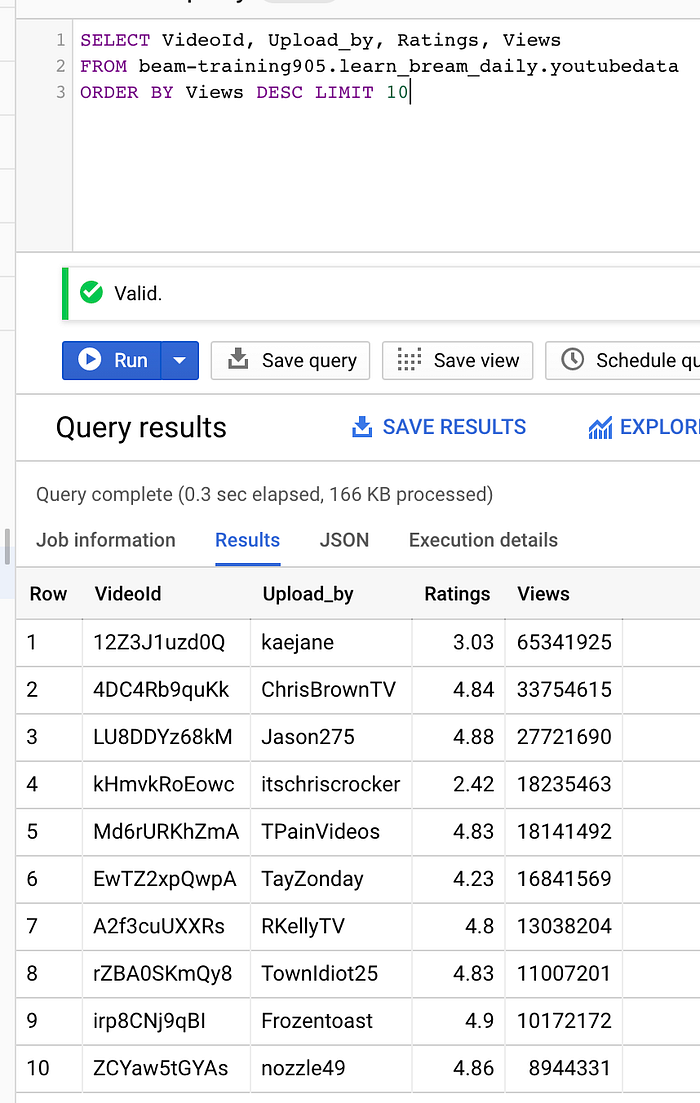
Top 10 Most Viewed Videos:
TO BE CONTINUED…..
